The Problem
AI can now analyze code so well that it can spot software vulnerabilities in just seconds. If you want a vivid explanation, Theo (t3.gg) breaks it down here. To make it simple: for decades, three assumptions kept software more secure – and now none of them hold up.
Here’s the first assumption: finding exploits took highly paid experts. That’s what kept attackers limited. AI erased that overnight. Now, anyone with enough computing power and a model can zero in on vulnerabilities in real software in minutes.
Second: the 90-day window for coordinated disclosure was supposed to be enough time. If you spotted a bug, maintainers had 90 days to patch and roll it out before everyone found out. That relied on assumption one. Without it, the window vanishes – two independent researchers found a huge Linux kernel exploit within nine hours of each other.
Third: going from patch to a working exploit was hard. Maintainers used to merge fixes quietly, with bland commit messages, hoping to buy time before attackers figured it out. AI ended that, too. Feed a four-line code diff into an AI model, ask if it looks like a security patch, and two out of three major models nail it right away – without reading the commit message. Now, the pipeline from patch to exploit is automatable.
So now, every piece of software, especially open-source, is exposed to zero-days at a speed and scale no one’s seen before. And as AI keeps improving, it only gets worse. Vulnerabilities are found faster and faster, but patching sticks to its old pace. That gap? It grows every month.
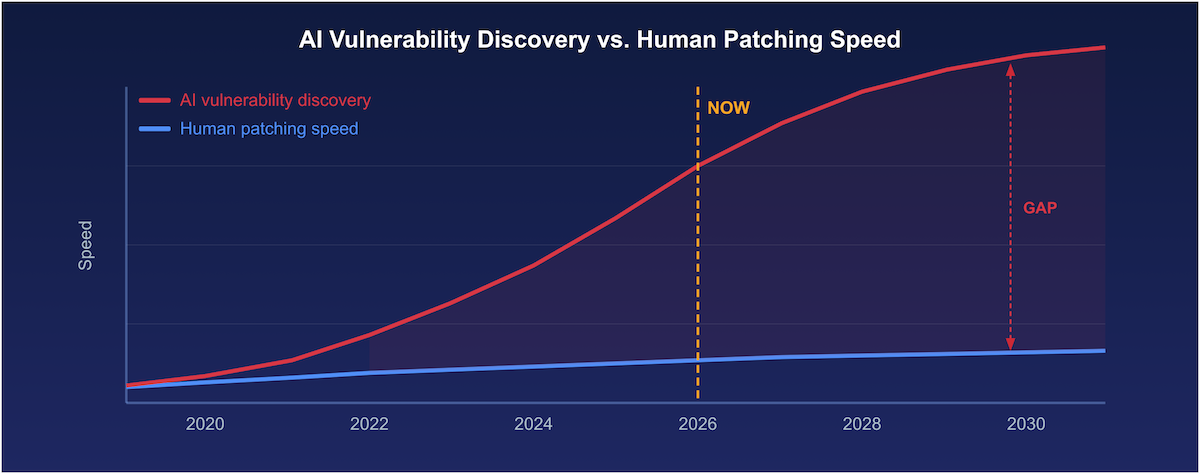 Figure 1: AI vulnerability discovery speed is rising rapidly while human patching speed stays flat. The gap will keep widening as models improve.
Figure 1: AI vulnerability discovery speed is rising rapidly while human patching speed stays flat. The gap will keep widening as models improve.Why Conventional Responses Are Not Enough
Patching Faster
The obvious answer is patching faster. If AI finds bugs quicker, use it to patch them faster, too. Sure, you shave off some risk around the edges, but it changes nothing fundamental. The attack surface never shrinks. AI scanners just jump to the next bug. Patching faster is like sprinting on a treadmill – you’re not getting off it.
Getting Rid of Open-Source
More drastic: kill open-source. If the source isn’t public, AI can’t analyze it directly. For a brief moment, that might slow things down.
But it won’t stop AI for long. Without source code, AI can reverse-engineer binaries. Obfuscation slows that, but now we’re locked in a never-ending battle of AI obfuscation versus AI deobfuscation. There’s no clear winner here. If your software runs strictly on the backend and never gets distributed, attackers just probe the backend via its public interfaces with crafted requests. AI is fantastic at that, too.
Honestly, we all love open-source. It’s one of the most powerful drivers software’s ever had. Closing it would be a huge loss with minimal security advantage. The answer here is no.
The Root Cause: Too Much to Attack
Both patching faster and hiding source code try to win the same race with AI. Neither deals with why this race is so brutal.
The real issue is the attack surface size. A typical production app pulls in hundreds of third-party libraries. Each of those pulls in more. The code available for AI to scan is a hundred times bigger than what the developer actually wrote. Most of it has never been read or audited by anyone on the team. It’s all public, constantly scanned, and grows with every install.
Attackers now target code developers trusted, not just code developers wrote themselves. Look at supply chain attacks: the 84 Tanstack packages compromised, CopyFail exploits in Python libraries, CI pipeline attacks – they all exploited dependencies, not application logic.
If you can’t win by running faster, shrink what you’re racing to protect.
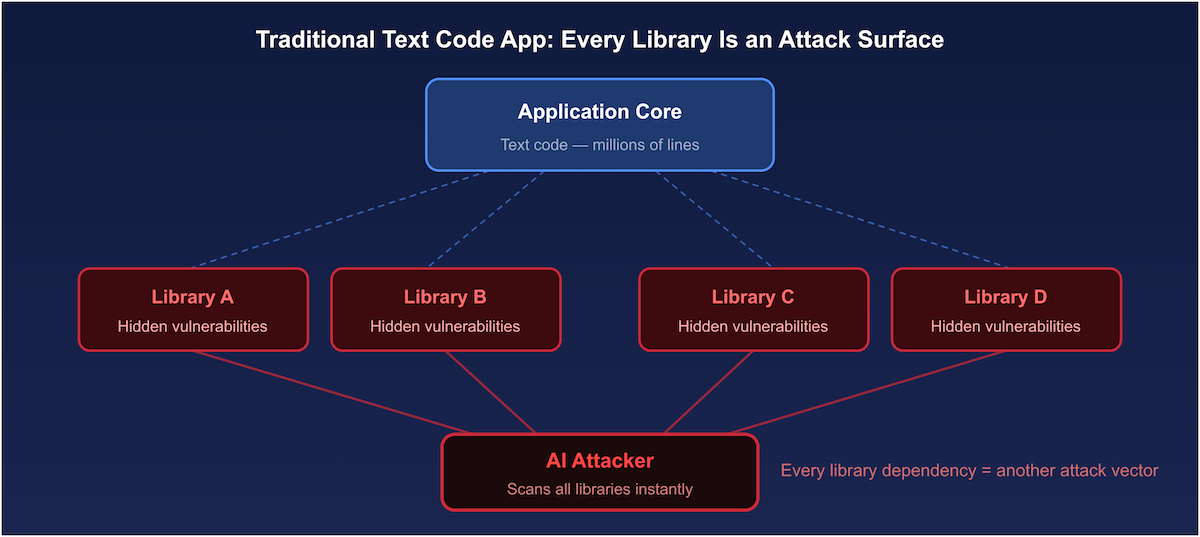 Figure 2: Every third-party library in a traditional text-based application is an independently exploitable attack surface continuously scanned by AI.
Figure 2: Every third-party library in a traditional text-based application is an independently exploitable attack surface continuously scanned by AI.Making Software Easier to Patch: The Visual Programming Direction
One practical way forward is to make patching easier by breaking apps into small, independently replaceable parts. The finer the granularity, the better – smaller components mean you can replace or isolate just the affected piece without shutting down or rewriting large chunks of the application. A vulnerability in one small component should stay contained, not cascade through the system.
Plugin architectures take this approach. Smaller parts mean smaller attack surfaces, and you can patch just the component instead of the whole system. But plugins still rely on third-party libraries, so attack surfaces don't really shrink. Plugin systems also pile on their own headaches: more to manage, compatibility issues between versions, more complexity as the number of plugins grows. Many of these problems come down to tight coupling – plugins are still deeply wired into the host application, making them harder to replace cleanly than they appear.
Microservices were designed specifically to address this. By moving to a loosely-coupled architecture where each service communicates through explicit, well-defined interfaces, you get true independence – one service can be replaced, redeployed, or taken offline without touching the others. A vulnerability in one service stays isolated.
But for most projects, the overhead becomes the real problem. Dozens of services means dozens of APIs to version, monitor, secure, and keep compatible. The infrastructure cost – service discovery, load balancing, distributed tracing, inter-service authentication – can dwarf the original application. This is why many small and mid-size teams are moving away from microservices toward modular monoliths. The cure became more expensive than the disease.
The pattern is consistent across all these approaches: the finer the granularity, the better the control, but the higher the cost – more infrastructure, more interfaces to maintain, and a mental model of how everything connects that gets increasingly hard to hold in your head. No text-based architectural approach has resolved this tension. It only moves it around.
Visual programming languages (VPLs) break this pattern. They offer maximum granularity – every block is its own independently replaceable component – while solving or mitigating the overhead problems that plague text code solutions. This is what makes VPLs fundamentally better than any text-based architectural approach: the same granularity, with none or minimum of the downsides.
In a VPL, each block on a diagram acts as a standalone, replaceable component. Unlike text-based components, VPLs give full transparency: the logic is right there on the diagram. Any developer can look at it and quickly understand what the program does without digging through code. Swapping a block doesn't require recompilation – it just needs to fit with the blocks it connects to. Patching becomes as easy as drag-and-drop.
These blocks are simple to replace and isolate. If one's compromised, you can disconnect or disable it immediately and interactively without recompiling, minimizing collateral damage while preparing a fix.
Transparency matters for security beyond just patching. With text, the logic connecting components is more hidden – you have to read code to understand it. In a visual program, it's laid out in the diagram. No room for hidden connections.
Composable Blocks and the Visual Hierarchy
A well-designed VPL goes further than a flat diagram of blocks. Blocks are composable: any block can contain other blocks inside it, forming a hierarchy of arbitrary depth. High-level business logic sits at the top. Each block can be opened to reveal its internal workflow. The hierarchy goes all the way down to the bottom level, where blocks contain no further sub-blocks. These are called leaf blocks, and they are the only place in the hierarchy where code lives.
This composability is what makes a VPL suitable for large, complex applications rather than toy examples. The top-level diagram stays clean and readable. Complexity is encapsulated inside blocks. Any level of the hierarchy is independently replaceable without touching the rest.
There is another advantage that is easy to miss: increasing granularity in a VPL is trivial. In a text-based plugin or microservice architecture, splitting a component into finer pieces means rewriting code, updating interfaces, and often changing infrastructure – service registries, load balancers, deployment configurations. It is expensive enough that teams often avoid it even when they know finer granularity would be better. In a VPL, splitting a block into smaller sub-blocks is a visual operation. You open the block, draw the internal workflow, and connect the pieces. No infrastructure changes, no interface rewrites, no ripple effects through the rest of the system. The cost of increasing granularity drops to near zero, which means teams can afford to do it whenever it makes sense rather than only when the pain of not doing it becomes unbearable.
This is the compounding advantage of VPLs over all text-based architectural approaches: not just that maximum granularity is available, but that reaching and adjusting that granularity is effortless compared to anything else available today.
VPL Impact on Software Self-Healing Technology
Self-healing technology can automatically find and fix bugs in your code. But here is the catch with traditional approaches: the fix still has to go through source code. Once identified, it needs code review, merge, and a full trip through the CI/CD pipeline across all environments before it reaches production. That takes time – sometimes hours, sometimes days. The problem sits live the whole time.
Visual programming changes the reaction time dramatically. A self-healing engine working with a VPL can pinpoint the exact block causing the problem and fix, isolate, or replace it right on production – immediately, without touching source code, without recompilation, without a deployment pipeline. The application keeps running. The problem is contained.
This buys the development team something valuable: breathing room. Instead of scrambling to push a hotfix through review and deployment as fast as possible while the issue is live, they can take the time to fix the source code properly – with full review, proper testing, and normal deployment. The in-place VPL fix holds the line while the real fix is done right.
This level of precision is simply not available in text-based systems. Large monolithic components cannot be modified in-place without a full recompilation. Even smaller text-based components have too coarse a granularity for surgical logic changes. The self-healing engine cannot get in without a full rebuild.
In a VPL, every block is independently replaceable at runtime. The boundaries are explicit, the hierarchy goes all the way down to individual leaf blocks, and no recompilation is needed to swap one out. That is what makes true in-place self-healing possible – and what makes VPL the natural platform for the next generation of software self-healing technology.
The VPL Security Model: Shrinking the Attack Surface
Third-Party Libraries as Visual Workflows
People usually think a visual app replaces all its outside libraries with AI-generated code. That’s not realistic. Libraries pack in too much functionality to recreate from scratch.
The realistic scenario: third-party libraries become visual workflows themselves. In a VPL ecosystem, a library is a visual workflow with a bit of code at the leaves for OS interaction. Applications mix these library visuals with their own.
This changes everything for security. If you find a bug in a library, you can dive in and fix it right in its workflow, since you see everything. Or you can wait for a patched version and drop in the new block. No need for recompiling or risking breakage elsewhere.
Either way, it’s faster, more transparent, and less risky than patching opaque text-based libraries – where changing one thing might break another.
The Leaf Code Layer: Where Vulnerability Lives
At the bottom of visual hierarchies sit the leaf blocks, the only place for code. These handle things like OS calls, file reads, network connections – the low-level stuff.
Leaf code can invoke text libraries. But you want to make dependencies here as thin as possible. The simpler the leaf code, the smaller the attack surface.
The first level of minimizing attack surface is AI code generation. If the dependency is small or simple, have AI build it directly instead of pulling in a library. That wipes out the dependency altogether – the new code isn’t public, so nothing for AI scanners to target.
The second level, as AI capabilities grow, is direct visual workflow generation. Rather than generating text code, AI will be able to generate complete visual workflows with a thin leaf code layer. This makes dependency self-production an even more attractive option: the generated component is not just functional but transparent, composable, and fully auditable as a visual workflow.
If you have to use third-party stuff, prefer VPL-based libraries. You get transparency and easy patching. Their attack surface beats opaque text libraries any day.
When all these practices are applied together, the application approaches the ideal state: no or minimum third-party library dependencies and maximum use of VPL-based libraries, with the attack surface reduced to the operating system or close to it.
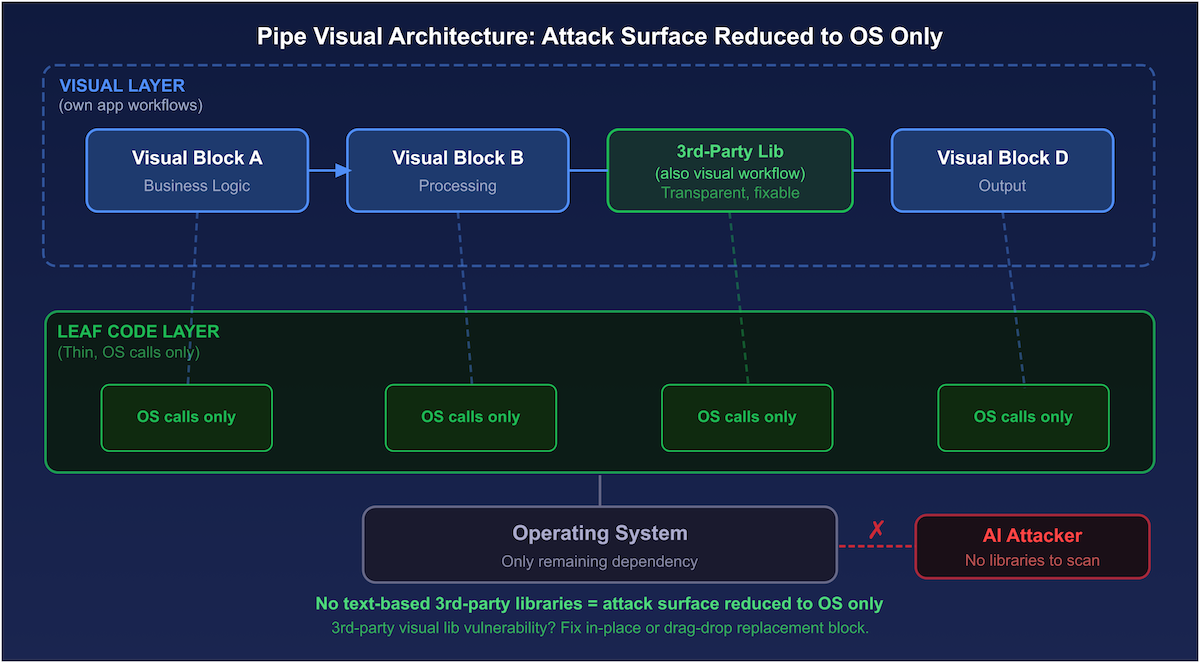 Figure 3: Visual application architecture. Third-party libraries are also visual workflows, fully transparent and patchable. Leaf code handles OS calls; the target is to keep it thin and text-based library-free. Attack surface collapses to the OS.
Figure 3: Visual application architecture. Third-party libraries are also visual workflows, fully transparent and patchable. Leaf code handles OS calls; the target is to keep it thin and text-based library-free. Attack surface collapses to the OS.Why Pipe Is the Right VPL
The Gap No Existing VPL Has Closed
Visual languages aren’t new – LabVIEW owns engineering, Simulink rules in aerospace, Node-RED is all over IoT, Unreal Blueprints for games. None of them fit the broad security needs outlined here. They're either built for niche domains, or just can't handle production-level complexity.
To truly shrink attack surfaces in production apps, a VPL has to be general-purpose enough to cover any domain, and robust enough for real-world code.
Pipe (pipelang.com) is built exactly for that. It’s general-purpose and sophisticated enough to handle production-level applications anywhere. Seven years went into its architecture, ten provisional USPTO patents cover its design, and you can check out the full language spec at pipelang.com.
How Pipe Implements Block Interfaces: Domains and Overlaps
In Pipe, each block input is analogous to an independent API endpoint. The interface of that endpoint is defined by a domain: a hierarchical data structure, a tree where each node can have both a value and children, similar to JSON but more expressive. Domains are assigned to block inputs and outputs. When two blocks hook up with different domains, Pipe resolves this with "overlaps": it lines up domain nodes with matching tree paths between the output and the input domains, passing data only between nodes where paths match. Unmatched nodes take explicitly defined or implicitly assumed default values.
That means almost any two Pipe blocks connect easily, even if their interfaces don't match up cleanly – with some exceptions such as data type compatibility between source and destination domain nodes. The domain overlap gives you flexible connections, making Pipe practical at scale. And Pipe guarantees interface contracts, so developers don't have to write validation at block boundaries.
This makes Pipe's block interfaces more loosely coupled than even conventional API interfaces. A standard API requires both sides to agree on an exact contract – matching field names, types, and structure. Any mismatch means the developer must write adapter code, update the contract, or handle errors explicitly. Pipe's domain overlap mechanism removes that requirement entirely. Blocks connect regardless of interface differences, with the language resolving mismatches automatically through defaults. Pipe rejects connectivity only when data types are incompatible or when domain nodes are marked as mandatory in overlap but missing. This is architecture at its loosest possible coupling: not just loosely coupled, but self-adapting, where the system resolves differences rather than the developer.
Addressing the Drawing Effort Concern
Some folks say visual diagrams take more effort to draw than typing a plain code. Here’s why that’s not a problem.
Pipe diagrams are naturally more compact. A block needing lots of input parameters doesn’t need separate lines for each – one domain connection carries everything. Seven parameters, one connection. Diagrams stay neat, even as logic grows.
Plus, Pipe lets you modify workflows with AI. Want to add blocks, reroute, restructure? Just describe it in natural language and Pipe does the work. Diagram maintenance gets as easy as telling the system what you want, not fussing with box placement.
The Security Spectrum
Not every app can jump straight to Pipe with slim leaf code, but every step toward it is a serious security boost.
- Step 1. Open-source text code and libraries: entire source and dependencies open to AI scanning. Biggest possible attack surface.
- Step 2. Closed-source text code with libraries: source hidden, but binaries are reverse-engineerable, APIs exposed. Libraries still wide open.
- Step 3. Pipe with some text libraries: dramatically shrinks the attack surface, but remaining text libraries still risky.
- Step 4. Pipe with visual library workflows and thin leaf code: almost no third-party library dependencies, only VPL-based ones. Attack surface drops down to mostly just the OS.
That last step is the end goal. You don’t need to get there instantly or completely – even moving partway over is already a big improvement from old-school architectures.
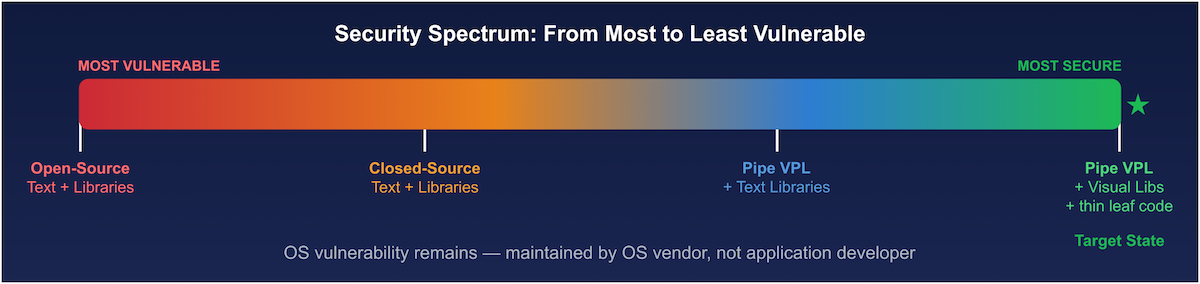 Figure 4: Security spectrum from most to least vulnerable. Each step right reduces the attack surface. The target state for Pipe leaves only the OS as an external dependency.
Figure 4: Security spectrum from most to least vulnerable. Each step right reduces the attack surface. The target state for Pipe leaves only the OS as an external dependency.Conclusion
AI made finding vulnerabilities cheap, fast, and possible for just about anyone. Patching faster helps a bit, but doesn’t address the real structural flaw. Killing open-source is a massive loss for little actual gain. The right answer? Reduce the attack surface.
Pipe, with libraries represented visually and leaf code kept thin for OS calls, gets you there. Everything is transparent and auditable at every level. You can isolate parts instantly. Patching is safer and faster. Supply chain risk from libraries is nearly gone. Remaining vulnerabilities shift to the OS – which the vendor maintains.
As AI generates more code faster, the need for VPLs such as Pipe will grow. The goal isn’t making software bulletproof, but making it fundamentally harder to exploit. When your only attack surface left is the operating system, you’ve actually achieved that.
Referenced video: Theo (t3.gg), "AI Is Hacking Everything Now..."