Executive Summary
Pipe is a general-purpose visual programming language designed to match the sophistication and power of traditional text-based languages like Java, Python, and C++. Built on five foundational pillars, Pipe solves the core challenges that have prevented visual programming from achieving widespread adoption in professional software development.
This document explains how Pipe's five architectural pillars enable professional-grade software development in a visual environment, making programming more accessible without sacrificing power or flexibility.
The Challenge: Why Visual Programming Hasn't Succeeded
Visual programming offers significant cognitive advantages over text-based programming — similar to how graphical user interfaces revolutionized computing by replacing command-line terminals. However, despite these advantages, visual programming has not replaced or even competed effectively with traditional programming languages.
The core problem: Most visual programming languages sacrifice either power or generality. They either have too simple element base that limits expressiveness, or they specialize in narrow domains (like game development or data science) at the cost of general-purpose capability.
Modern software development requires general-purpose languages with professional-grade capabilities. Pipe addresses this fundamental challenge through five carefully designed architectural pillars.
The Five Pillars of Pipe
Each pillar addresses a specific architectural challenge in visual programming, working together to create a language that is both powerful and practical.
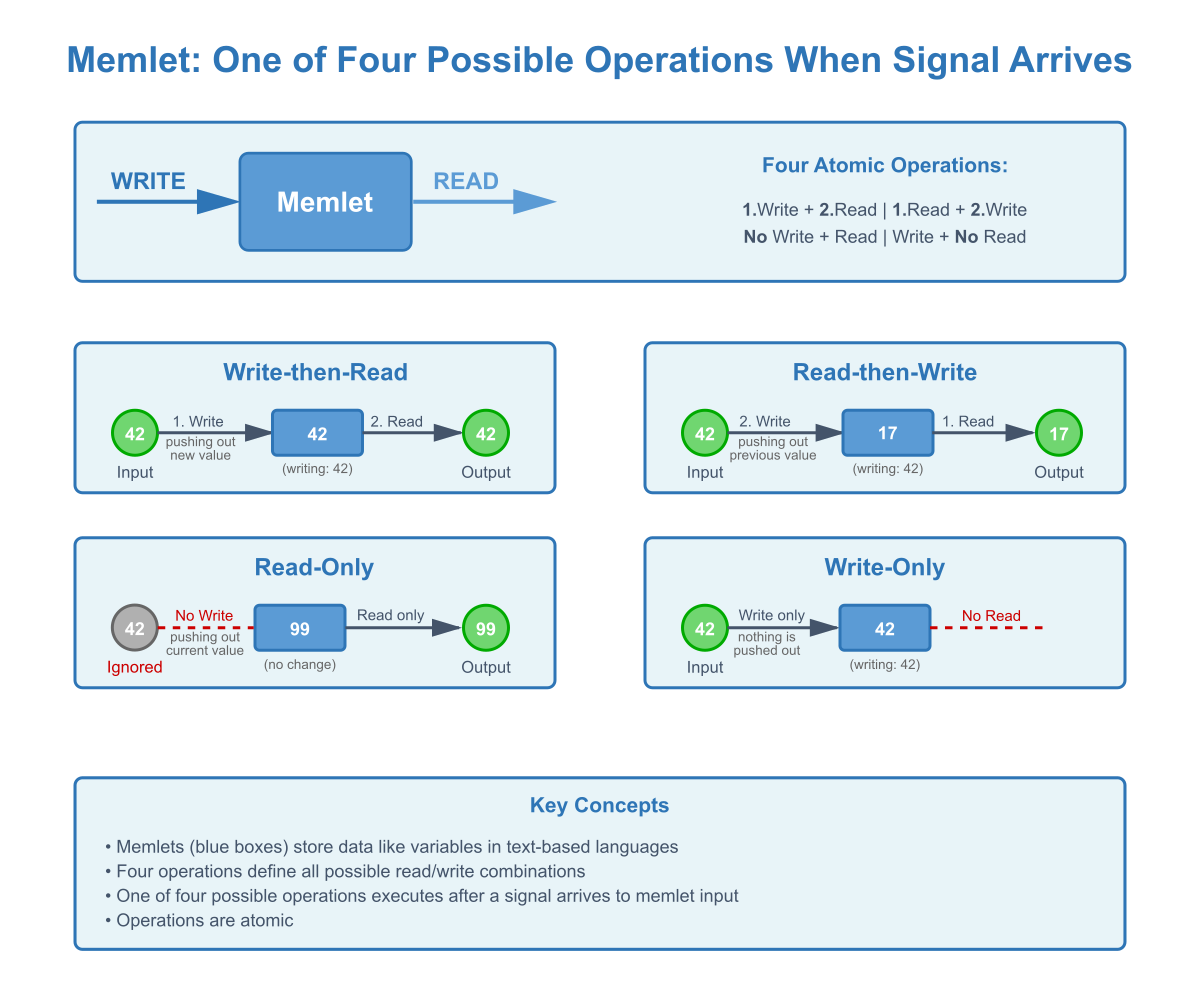
Pillar 1: Dedicated Memory Blocks (Memlets)
The Foundation: Many visual programming languages lack dedicated memory structures or keeping them out of visual diagram (implicit memory), making state management difficult or impossible. Pipe introduces 'memlets' — specialized memory blocks that mirror the role of variables in text-based languages. Memlets are always explicitly shown on diagrams.
Why It Matters: Any meaningful algorithm requires two components: memory (data storage) and processing (data manipulation). Without proper memory structures, visual languages remain limited to simple dataflow operations.
How Pipe Solves It: Memlets support four atomic operations that define all possible interactions with stored data (one of four operations executes for each input signal):
- Write-then-Read: Store new data, then output the stored value.
- Read-then-Write: Output current value, then update with new data.
- Read-Only: Output stored value without modification.
- Write-Only: Update stored value without output.
Real-World Example: Building a shopping cart requires storing items (Write-Only), displaying the total (Read-Only), updating quantities (Read-then-Write), and saving without displaying (Write-Only). Memlets make these operations explicit and manageable.
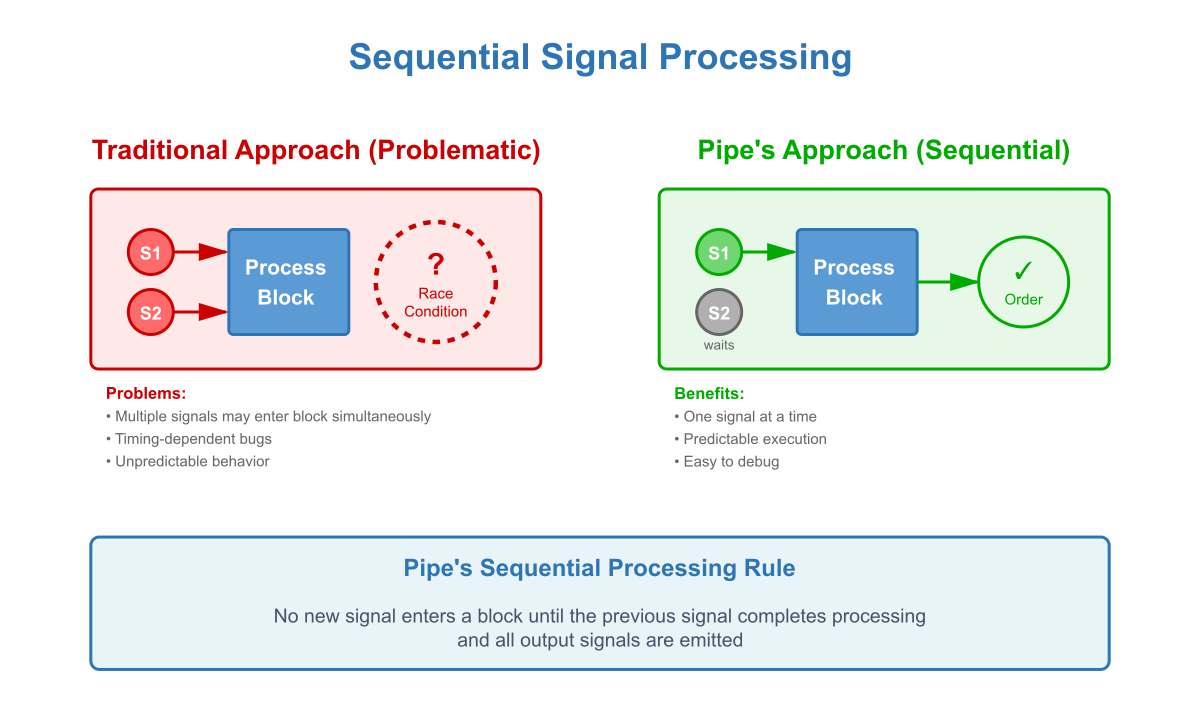
Pillar 2: Sequential Signal Processing
The Foundation: Traditional visual languages face a critical question: when should signals enter multi-input blocks? Most require all inputs to have signals present simultaneously, creating timing complexity and unpredictable behavior.
Why It Matters: Requiring simultaneous signal arrival leads to race conditions and timing bugs. Allowing unsynchronized entry creates chaos with multiple signals processing concurrently — making programs impossible to trace or debug.
How Pipe Solves It: Pipe implements a strict but elegant rule: signals can enter any input independently, but no new signal enters a block until the previous signal completes processing, and all outputs are emitted.
Benefits:
- Predictability: Execution order is always clear and deterministic.
- Traceability: Only one signal processes at a time, simplifying trace analysis.
- Simplicity: No race conditions or timing-dependent bugs.
Real-World Example: In a data processing pipeline, input signals can arrive at different rates from multiple sources. Sequential processing ensures each data packet completes its journey before the next begins, maintaining data integrity and making behavior predictable.
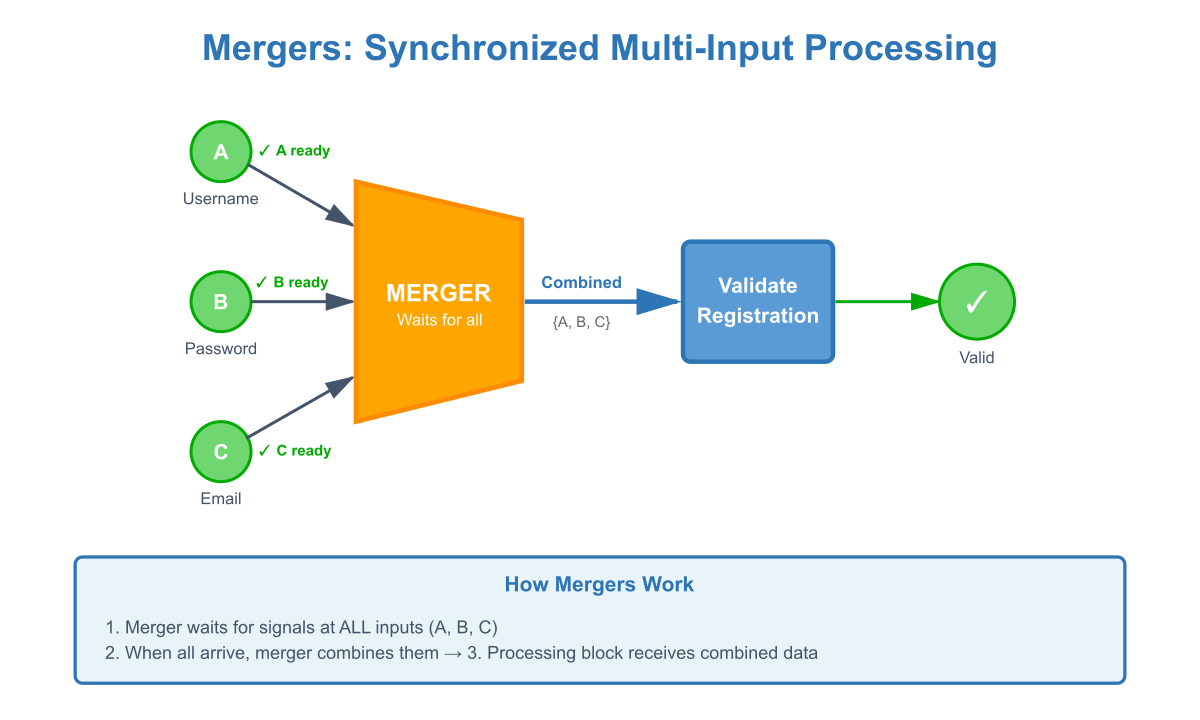
Pillar 3: Mergers for Synchronized Processing
The Foundation: Sequential processing solves timing problems, but sometimes you genuinely need to process multiple signals together. Mergers provide this capability without compromising the benefits of sequential execution.
Why It Matters: Many operations require multiple inputs — comparing values, combining data, coordinating actions. Without mergers, sequential processing would be too restrictive.
How Pipe Solves It: A merger is a special component that waits for signals at all its inputs, then combines them into a single output signal. Merger output can be fed into a regular processing block, which maintain sequential behavior.
Key Insight: Merger + Processing Block = Multi-input block with synchronized processing. This combination provides the flexibility of traditional multi-input blocks while preserving sequential processing benefits.
Real-World Example: When validating user registration, you need email, username and password to arrive before checking. A merger waits for all three inputs, combines them, and sends them together to the validation block — ensuring atomic checking of credentials.
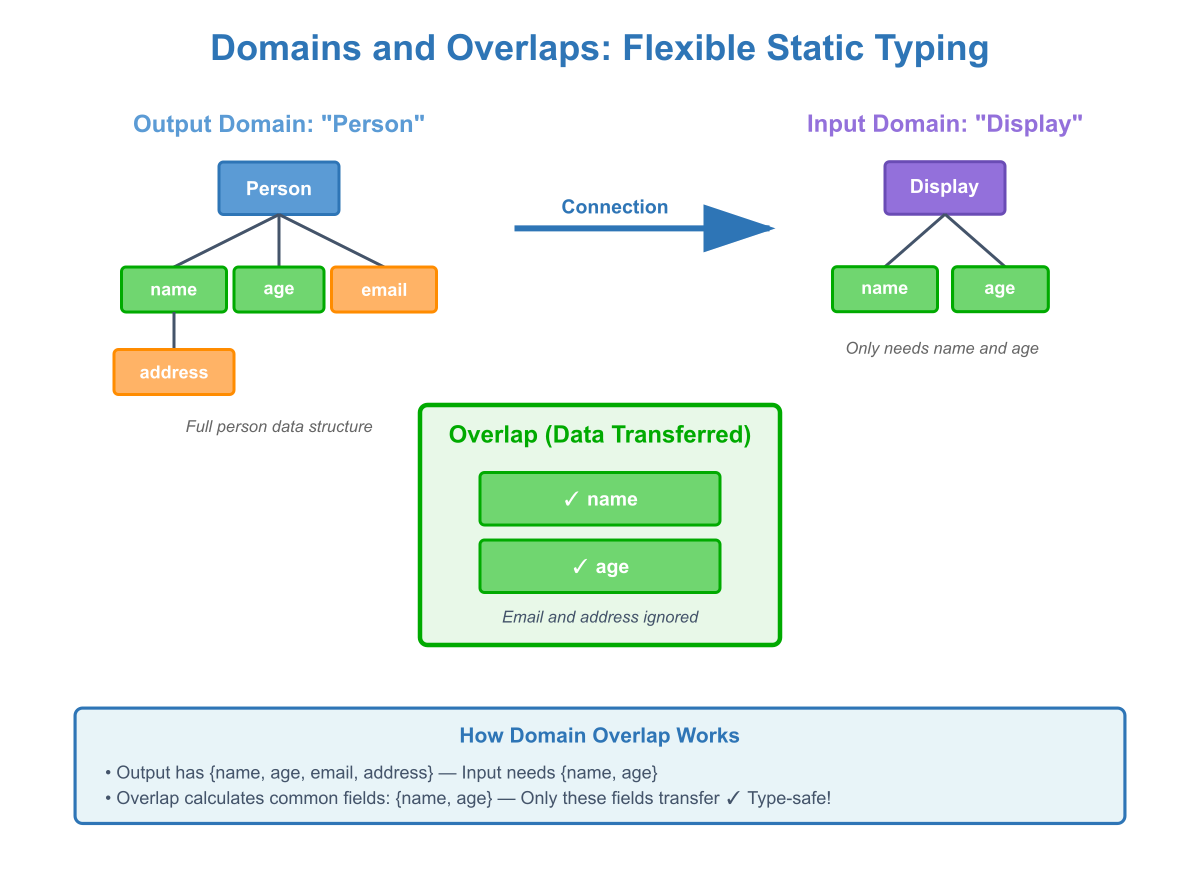
Pillar 4: Static Typing with Domains and Overlaps
The Foundation: Most visual languages allow arbitrary data over connections — equivalent to dynamically typed programming. Professional development demands static typing for reliability and maintainability. Pipe introduces 'domains' as tree-structured type definitions.
Why It Matters: Dynamically typed languages (JavaScript, Python) are harder to debug and maintain at scale. The most popular professional languages (Java, C++, C#, TypeScript) are statically typed for good reason — type checking catches errors early and makes code more reliable.
What Are Domains: Domains are tree-like data structures similar to JSON, but with additional features required for visual programming. Each block input, output, and memlet can be assigned a domain that defines its data structure.
The Innovation — Overlaps: When connecting blocks, outputs and inputs don't need identical domains. Instead, Pipe calculates the 'overlap' — the set of common tree nodes with matching paths. Data transfers only for overlapping tree nodes, providing tremendous flexibility.
Benefits:
- Flexibility: It is not required for types to be identical to connect blocks.
- Reusability: Blocks work with various input types through overlap.
- Safety: Static type checking at compile time prevents runtime errors.
Real-World Example: A 'person' block outputs {name, age, email, address}. A 'display' block expects {name, age}. The overlap is {name, age}, so the connection works — transferring relevant data while ignoring irrelevant fields. This flexibility enables modular design without rigid type matching.
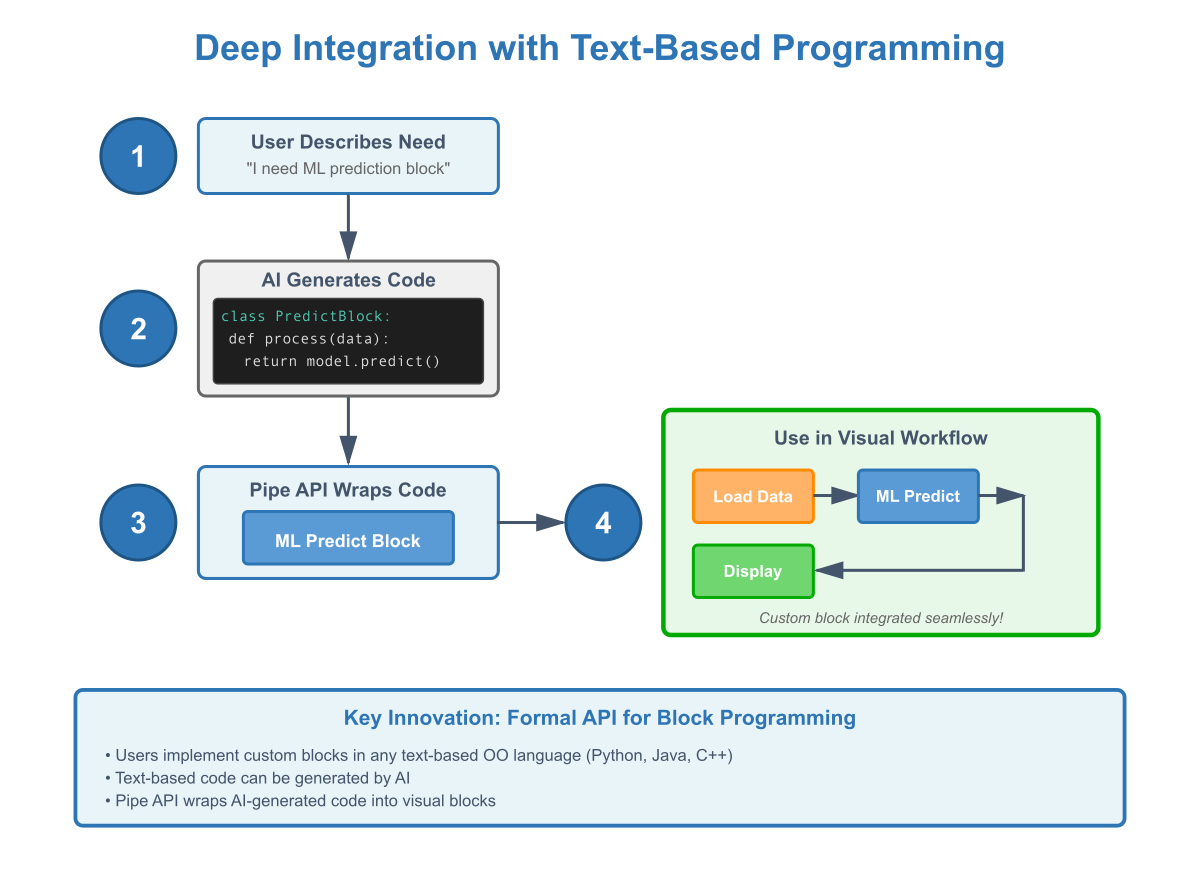
Pillar 5: Deep Integration with Text-Based Programming
The Foundation: Every visual language has an underlying text-based implementation. Domain-specific languages hardcode their visual blocks, limiting flexibility. Pipe recognizes that visual and textual programming must coexist and provides a complete formal API for programming visual blocks in any object-oriented language.
Why It Matters: Professional development requires extending and customizing tools. If visual blocks are fixed and hardcoded, the language cannot adapt to new requirements. General-purpose languages need extensibility.
How Pipe Solves It: Pipe provides a comprehensive API for implementing custom visual blocks using any object-oriented text-based language. Users can create their own blocks with custom logic, not just configure predefined ones.
The AI Integration Advantage: This deep integration makes Pipe the perfect companion for AI code generation tools. Users describe desired functionality, AI generates the textual implementation, and Pipe wraps it into visual blocks — combining visual workflow design with AI-powered code generation.
Real-World Example: Need a custom machine learning prediction block? Describe it to an AI assistant, receive Python code implementing the model, wrap it in a Pipe block, and integrate it visually into your application — no manual coding required.
Beyond the Five Pillars: Compact Representation
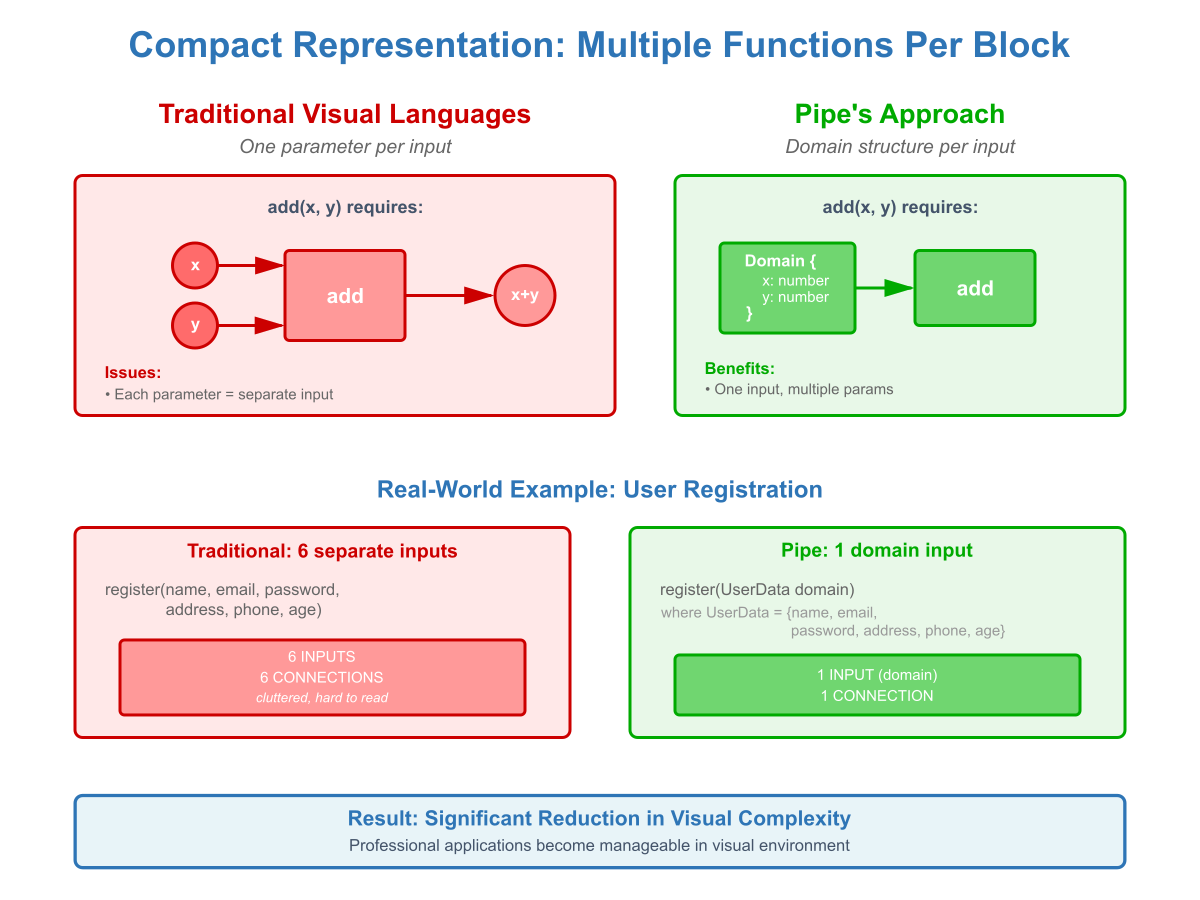
Sequential order of input signal processing and domain assignment to each input make visual workflows significantly more compact and manageable:
Traditional Approach: Most visual languages represent a function like 'add(x, y)' with two separate inputs — one for x, one for y. Each input accepts a single parameter. A block represents one function.
Pipe's Approach: Pipe combines multiple parameters into a single domain-typed input running independently from other inputs. For 'add(x, y)', both x and y are fields in one domain structure. Each input represents a complete function signature, not just a parameter.
The Result: A single Pipe block can represent multiple functions (one per input). This makes visual workflows dramatically more compact — significant reduction in visual complexity compared to traditional approaches.
Why It Matters: Visual programming's biggest challenge is screen space. By reducing the number of visual elements required, Pipe makes complex applications manageable in a visual environment.
Example of Pipe Diagram
Example of Pipe diagram for a real business case of calculating account interest is provided below:
Why This Matters: The Impact of Pipe
The five pillars work together to create something unprecedented: a visual programming language with professional-grade capabilities.
For Individual Developers:
- Reduced cognitive load through visual representation.
- Professional power without sacrificing ease of use.
- Seamless integration with AI code generation tools.
For Software Teams:
- Faster onboarding — visual programs are easier to understand.
- Better collaboration through visual communication.
- Maintained code quality through static typing and clear structure.
For the Industry:
- Democratizes programming while maintaining professional standards.
- Creates a bridge between visual design and code implementation.
- Enables a new paradigm: visual programming worthy of production software.
Want to Go Deeper?
These five architectural innovations are just the foundation. The full specification covers Pipe's complete language design.
Core Language Features
Beyond memlets, sequential processing, mergers, domains, and APIs, Pipe includes:
Processing Components:
- Runlets (prime, composite, fixed, inline, mutators, testers, etc.) — different block types for different needs.
- Synclets — shapes ensuring synchronous processing.
- Transformers & Translets — domain modifications.
- Beacons — application startup and shutdown control.
- Mergers — merging signals together.
Memory & State:
- Membanks — share memory accessible by multiple memlets.
- Memlet bond attributes — specifying memlet operations (write-then-read, read-then-write, etc.).
- Broadcast bond attribute — activating all memlets in a membank simultaneously.
- Component state management and overrides.
Advanced Type System:
- Domain specification with node attributes and modifiers.
- Attribute grouping mechanism.
- Complete overlap calculation and validation rules.
- Domain inheritance and assignment.
Error Handling:
- Traplets — exception handling blocks with formal exception specification.
- Exception codes and propagation rules.
Connectivity:
- Multi-point connections.
- Six Signal Distribution and Processing (SDP) rules.
- Carrier vs. blank signals.
Application Structure:
- Projects and solutions.
- Application connectivity with virtual machine.
Complete Visual Notation System
The specification includes comprehensive notation for:
- Diagram colors and orientation.
- Visual representation for every component type.
- Comment blocks and documentation patterns.
- Common diagram elements and conventions.
Runlet API Specification
Full API documentation for implementing blocks in:
- Python
- Java
- C++
- Any other object-oriented language
Enables the workflow: describe need → AI generates code → wrap in Pipe block → integrate visually
Real-World Applications
The specification includes detailed examples:
Basic Patterns:
- "Hello World!" Pipe application.
- Iteration patterns.
- Callback mechanisms.
- Recursion using dynamic runlets.
Professional Application:
- Interest calculation system — real business case with 13 blocks across 4 workflow scenarios, demonstrating how Pipe handles complex financial logic.
Troubleshooting:
- Six most common issues and solutions.
- Best practices and anti-patterns.
Standard Library:
- Standard library for common cases (math, collections, etc.).
- Future extensions.
Formal Treatment
- Type system rules — complete formal specification.
- Operational semantics — how Pipe programs execute.
- Design rationale — why specific decisions were made.
- Future development roadmap.